
TL;DR Restic
Všichni víme, že jednoduché věci fungují nejlépe, a tak jsme dlouhou dobu používali (především pro lokální zálohy) rsync s rozdílovou zálohou pomocí hardlinků (kouzelný parametr –link-dest). Měli jsme tak snapshoty po jednotlivých dnech bez toho, aby zbytečně narůstala velikost zálohy.
Skript pak vypadal zhruba takto:
#vytvoreni denni zalohy
date=`date "+%Y-%m-%d"`
rsync -aP --link-dest=/backup/htdocs/latest /srv/htdocs/ /backup/htdocs/$date
#symlink na posledni zalohu k porovnani - odstranit a vytvorit novy
rm -f /backup/htdocs/latest
ln -sf /backup/htdocs/$date /backup/htdocs/latest
Staré zálohy pak stačilo jednou za čas odstranit, což ale byla vcelku náročná operace. Pro lokální zálohu to fungovalo skvěle. Mnoho vzdálených úložišť však hardlinky nepodporuje, a proto jsme pro vzdálenou zálohu hledali jiné řešení. Nějakou dobu nám vcelku dobře složil BUP, což je vlastně repozitář založený na gitu, kdy jsou větší binární soubory rozděleny na menší části a je s nimi pak jednotlivě nakládáno – funguje tak částečná deduplikace a tento typ záloh se hodí i například na zálohování virtuálních strojů, které vycházejí ze stejného základu. Nevýhodou je pomalost a náročnost obnovy v případě, že je repozitář velký, neboť odstraňování starých záloh je velmi komplikované.
Pokud zálohujete do nějaké externí služby, je velmi vhodné data šifrovat. S tím ale BUP přímo nepočítá. Řešili jsme to tak, že jsme nejprve data k záloze uložili na svazek šifrovaný pomocí LUKS a zálohovali jsme až šifrovaná data. Oživení zálohy se tím tak také trošku zkomplikovalo. Samozřejmě jsme nebyli jediní, koho tento problém trápil, a tak vznikly další projekty pro jeho řešení – např. https://github.com/skorokithakis/encbup
Příklad zálohovacího skriptu
#export BUP_DIR="/mnt/samba/bup/"
bup index -ux /mnt/enc/htdocs/
bup save -n htdocs /mnt/enc/htdocs/
Takto nám zálohování sice dlouho fungovalo bez větších problémů, ale práce se zálohami nebyla úplně jednoduchá, což nás motivovalo k hledání náhrady.
Požadavky:
- levné
- šifrované
- rozdílové/deduplikované
- přívětivé
Velcí cloudoví poskytovatelé dnes nabízejí službu “Object storage”, která je levná a vhodná pro ukládání nestrukturovaných dat a pokud si strukturu udržujete vlastními silami, tak je vhodná i pro zálohy. Chtěli jsme toho tedy samozřejmě využít.
Ultimátní nástroj, který splňuje všechny naše požadavky, se jmenuje Restic.
Podobně jako BUP je založen na repozitáři, rovnou však počítá se šifrováním a odstraňováním starých záloh. Další výhodou je to, že podporuje mnoho služeb. Pro nás konkrétně je klíčová podpora úložišť kompatibilních s Amazon S3 – to je například levný Digital Ocean Spaces. Samozřejmě umí i lokální zálohu, zálohu po SSH, vlastní REST server, Azure i Google Cloud Storage. Pokud hledáte opravdu levné úložiště a nevadí vám vyšší latence (datacentra mají v USA), můžete zkusit Backblaze B2 s cenou 0,005$ za GB.
My sami využíváme právě Digital Ocean Spaces v Amsterodamu v sazbě 0,02$ za GB.
Pojďme se nyní podívat, jak se Restic v používá a co všechno umí. Ukážeme si to na příkladu zálohy do Spaces. Nejprve budeme potřebovat několik ENV proměnných s údaji o repozitáři:
export AWS_ACCESS_KEY_ID=""
export AWS_SECRET_ACCESS_KEY=""
export RESTIC_REPOSITORY="s3:ams3.digitaloceanspaces.com/"
export RESTIC_PASSWORD=""
Můžeme si všimnout, že rovnou nastavujeme proměnou s heslem – toto heslo bude sloužit k šifrování dat pomocí AES-256. Je dobré si ho poznamenat do správce hesel. Pro dešifrování repozitáře je možné nastavit i více různých hesel. Repozitář lze samozřejmě zadat i z příkazové řádky (-r) a heslo nechat vyplnit při spuštění.
Pokud máme nastavené proměnné, musíme nejprve repozitář inicializovat:
restic init
Ve Spaces se nám ukážou zárodky našeho nového repozitáře:
Vše je připraveno k záloze:
restic backup /cesta/k/souborum
Hotovo.
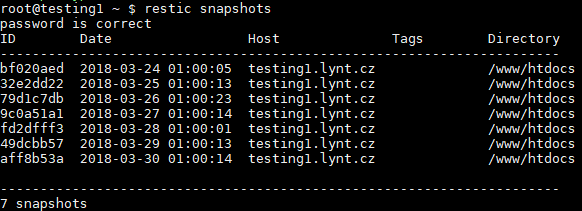
Nyní se můžeme podívat na jednotlivé zálohy:
restic snapshots
Je dobré také provést kontrolu konzistence a ujistit se, že jsou data v pořádku:
restic check
A samozřejmě můžeme zálohu jednoduše obnovit zpět:
restic restore latest --target /kam/obnovit
S těmito několika příkazy zvládnete základní zálohování. Restic však nabízí mnohem více kontroly.
Jednoduše můžete porovnat změny v jednotlivých zálohách, stačí si z restic snapshots zjistit jejich ID. Porovnáte je pak pomocí restic diff id-a id-b. Díky ID zálohy můžete také obnovit jednu konkrétní zálohu.
Pokud máte nainstalováno FUSE, tak můžete celý repozitář přimountovat přímo do složky a zálohy procházet ve filesystému – můžete si tak vylovit konkrétní soubor. Zálohy jsou roztříděny do složek podle několika parametrů:
- hosts – pokud do jednoho repozitáře zálohujete z více strojů, jsou zde zálohy roztříděny podle hostname
- ids – zde jsou zálohy podle svých ID
- snapshots – zde je třídění podle času vytvoření zálohy
- tags – při zálohování můžete přidávat jednotlivým zálohám tagy – hodí se to v případě, že do jednoho repozitáře zálohujete více různých zdrojů. Tag záloze přidáte při záloze parametrem –tag, nebo je můžete dále spravovat příkazem
restic tags.
Obnovit konkrétní soubor můžete i pomocí restic dump – příkaz vypíše daný soubor na stdin. Soubory v záloze si můžete vylistovat pomocí restic ls.
Pro práci se starými zálohami je zde mocný příkaz restic forget. Můžete ho používat jednoduše – restic forget – nebo můžete využít mnoho užitečných parametrů:
–keep-last N – ponechá pouze posledních N záloh
–keep-tag TAG – ponechá pouze zálohy s daným tagem (tento parametr lze použít vícekrát)
–keep-[hourly/daily/weekly/monthly/yearly] N – ponechá pouze N zálohy dle vybraného časového období, díky tomu můžete vytvářet komplexní podmínky pro uchovávání záloh
Příklad:
restic forget --keep-daily 7 --keep-weekly 4 --keep-monthly 12 --keep-yearly 3
V repozitáři vám tak zůstanou zálohy 3 roky zpět následovně:
- 7 dní zpětně každý den
- 4 týdenní zálohy
- 12 měsíčních
- 3 roční
Je třeba zmínit, že příkaz forget reálně data nemaže – pouze je odlinkuje. Pokud chcete data opravdu odstranit a uvolnit místo v repozitáři, je nutné spustit příkaz restic prune, který odlinkovaná data opravdu smaže a uvolní místo – jedná se o dost náročnou operaci a je dobré po ní pustit check.
Primitivní zálohovací skript zálohu dat webového serveru a databáze by pak mohl vypadat například takto:
#! /bin/bash
MYSQL=/usr/bin/mysql
MYSQLDUMP=/usr/bin/mysqldump
ARCHIVE=/usr/bin/pigz
RESTIC=/usr/local/bin/restic
BACKUP_DIR=/www/htdocs
export AWS_ACCESS_KEY_ID=""
export AWS_SECRET_ACCESS_KEY=""
export RESTIC_PASSWORD=""
#$RESTIC init
#Backup MySQL
export RESTIC_REPOSITORY="s3:ams3.digitaloceanspaces.com/lynt-test-db"
databases=`$MYSQL -e "SHOW DATABASES;" | grep -Ev "(Database|information_schema|performance_schema)"`
for db in $databases; do
$MYSQLDUMP --opt --single-transaction --skip-lock-tables --databases $db | $ARCHIVE | $RESTIC backup --tag $db --stdin --stdin-filename $db.sql.gz
done
#Cleanup
$RESTIC forget --keep-daily 7 --keep-weekly 4 --keep-monthly 12 --keep-yearly 3
#$RESTIC prune
#Backup files
export RESTIC_REPOSITORY="s3:ams3.digitaloceanspaces.com/lynt-test-web"
$RESTIC backup --exclude-file /etc/restic-exclude.conf $BACKUP_DIR
#Cleanup
$RESTIC forget --keep-daily 7 --keep-weekly 4 --keep-monthly 12 --keep-yearly 3
#$RESTIC prune
Můžete si všimnout, že databázi zálohujeme přímo dumpem na stdin resticu – to je další možnost, jak jej používat. Pro zálohování databáze lze použít několik přístupů, které se liší hospodárností. Pokud je hlavním cílem ušetřit místo, lze dělat diferenciální zálohu, kdy se zálohují jen změněné řádky. Nicméně vzrůstá složitost obnovy. Raději tedy zálohujeme kompletní komprimovanou databázi v gzip (používáme k tomu nástroj pigz – na více jádrech je rychlejší).
Možná vás napadne, že by bylo vhodnější zálohovat nekomprimovanou DB, aby lépe zapracovala deduplikace. Restic ale používá deduplikaci na úrovni bloků, a tak i malá změna vstupních dat razantně změní obsah jednotlivých bloků. Pokusili jsme se to potvrdit testem:
Vzali jsme 300 MB dump databáze a zkoumali přírůstky při zálohách:
- nekomprimovaná DB – 300 MB první záloha, každá další +150 MB
- komprimovaná DB – 35 MB první záloha, každá další +35 MB
- komprimovaná DB s parametrem -rsyncable – výsledky prakticky stejné jako bez parametru
Při záloze rovnou vylučujeme nepotřebné soubory – logy, temp, cache, atd. Náš restic-exclude.conf tak vypadá následovně:
**/temp/**
**/tmp/**
**/.git/**
**/log/**
**/logs/**
**/cache/**
**/sessions/**
Pro zápis výjimek se používá běžný glob formát a je nutné v něm obsáhnout celou absolutní cestu (tip: otestovat si to můžete na http://www.globtester.com/).
Pro jednoduchost i úsporu místa se tedy vyplatí zálohovat kompletní komprimovaný dump databáze. Můžete si také všimnout, že všechny DB nahráváme do stejného repozitáře – při malém počtu souborů to nemá vliv na rychlost zálohování a trošku si tím ulehčíme práci. Aby byl repozitář přehledný, rovnou si jednotlivé databáze tagujeme jejich jménem.
Rychlost zálohování je v našich podmínkách následující:
Webserver – 200 GB dat, 3 miliony souborů, několik desítek webů, 100mbit konektivita
- prvotní záloha: 5 hodin, zabráno 190 GB dat (několik desítek webů)
- následná záloha: 20 minut scan souborů, 40 minut zálohování
VPS – 10 GB dat, 100k souborů, 1 projekt, 1Gbit konektivita
- prvotní záloha: 20 minut, zabráno 10 GB dat
- následná záloha: 1 minuta scan souborů, 3 minuty zálohování
Je vidět, že pokud máte server s více projekty, může být vhodnější zálohovat každý projekt zvlášť. Pak však nesmíte na žádný z projektů zapomenout 😉
Příkazu restic backup můžete dát i více adresářů najedou a vše pěkně funguje – s jedinou drobnou výjimkou. Pokud máte následující strukturu
/www/web1/htdocs
/www/web2/htdocs
a zazálohujete příkazem restic backup /www/web1/htdocs /www/web2/htdocs, Restic zahlásí “name collision” a přejmenuje vám druhý htdocs na htdocs-1. Pokud by vám to vadilo, můžete pustit zálohu o několik úrovní výše a pohrát si s výjimkami. V budoucích verzích by toto chování mělo být upravené.
Doufáme, že vám tento článek ukázal, jak může být zálohování jednoduché a Restic alespoň zkusíte. Budeme rádi, když se o své oblíbené zálohovací metody podělíte v komentářích.