This is a nasty problem because it is possible to get current and past files with a lot of information about the website’s structure, and sometimes you can get very sensitive data such as database passwords, API keys, development IDE settings, and so on. However, this data shouldn’t be stored in the repository, but in previous scans of various security issues, I have found many developers that do not follow these best practices.
Let me explain the problem. If you use git to deploy your site, you shouldn’t leave the .git folder in a publicly accessible part of the site. If you already have it there for some reason, you need to ensure that access to the .git folder is blocked from the outside world. You can easily verify these rules by trying to open the /.git/HEAD – if setup correctly it shouldn’t be working. This vulnerability is really tricky and it can be easily overlooked. If you only visit /.git/ directly you will get an HTTP 403 error in most cases. It seems as though the access is denied, but it is only a false sense of security. Actually, the 403 error is caused by the missing index.html or index.php and disabled autoindex functionality. However, access to the files is still possible. If you try it and the directory structure appears, the problem is even worse and the repository can then be downloaded much more easily and may be found on Google. The git repository has a well-known structure, so you can simply download individual files and parse the references to the individual objects/packs in the repository. Then you can download them via the direct request. This method allows you to reconstruct a large part of the repo. There are even tools that allow you to automate this – GitTools.
Even without relatively tedious reconstruction, you can get a lot of information about the site. From the /.git/index binary file, you can derive an application structure – libraries used, interesting endpoints (e.g. file uploaders), etc. If you are not a fan of finding strings in a binary file, there is a helper to decode it – Gin.
Of course, there are exceptions where the repository’s accessibility isn’t a problem – e.g. all the content is already shared on GitHub, or it is composed of only a few static files. However, even in these cases, I think access to files and folders beginning with a dot (except .well-known) should not be possible. So, I have prepared the rules for Nginx and Apache to block access to these files.
Let’s go back to the scan itself. I started the same way I do most of my other scans – compiled a list of sites to check, wrote a scanning script (Python, Requests, Concurrent.futures + ThreadPoolExecutor), processed the results and alerted the affected sites.
- list – from my previous research I already have a relatively extensive database of the Czech websites – I have compiled it for the WP Czech research and for the most part I shared it with Spaze. The first point has been resolved – about 1.5 million domains to explore.
- script – the scripts from previous scans were quite similar, so I’ve modified them to keep track of the presence of the /.git/HEAD file and the “refs” string in it.
- results – after less than 2 days I have found 1,925 Czech sites with an accessible .git repository. On a small control sample, I verified the severity – I found both passwords in DB and unauthenticated uploaders.
- contacts – the last step was to find contacts and reach out to them, this is always the most demanding part, especially when you have almost 2,000 sites…
In these cases, you need to prioritize – when a problem is presented on a large popular site, the impact can be far worse than in the case of a small forgotten page. My procedure may not be 100% fair, but I have a process for it – I make screenshots if all sites with a selenium browser script and then “the game” follows. I browse them in the image viewer and select the most interesting ones with a Steam Controller.
The priorities:
- known popular sites (big risk – many visitors can be affected)
- developers, and web agencies (risk of making similar mistakes for their clients)
- interesting sites “doing something good”
I’m able to sort through this amount of sites in around 1.5 hours. The next step is to look for contacts – it’s mostly manual work with uncertain results because email often doesn’t reach a relevant person. I manually found and contacted the first 200 affected sites. At this point I realized there is a much better way to do it – there is a list of commits in the /.git/ logs/HEAD file and it usually contains the email address of the developers who make commits (not all email addresses are usable but a large number of them are valid). This is a great way to automate notifications. So I wrote another script that processed these files and got the developers’ emails from them.
This was a great success! I sent almost 2,000 alerts to the relevant people with ease. A month after sending the alerts I did a rescan and the .git was accessible on just 874 sites. That’s a 55% success rate.
With a large part of the process now automated, I decided to repeat this for Slovakia.
- list – I used a list of domains provided directly by SK-NIC
- script – the script was the same
- result – in less than a day I found 931 open git sites
- contact – I automatically sent the notifications
Easy!
Since it was so easy to scan these two states, how difficult could it be to scan the entire world?
The answer – very very difficult!
The first task was to get a list of domains for scanning. Again I had a few from the previous scans (e.g. from Alexa Top Million – download), but you need more of them for a truly global scan. It was necessary to create a new list. So, I used DNS log from the OpenData Rapid 7 project. This was a 3.5TB text file in JSON format, which shows the individual queries:
{"timestamp":"1530259463","name":"","type":"","value":""}
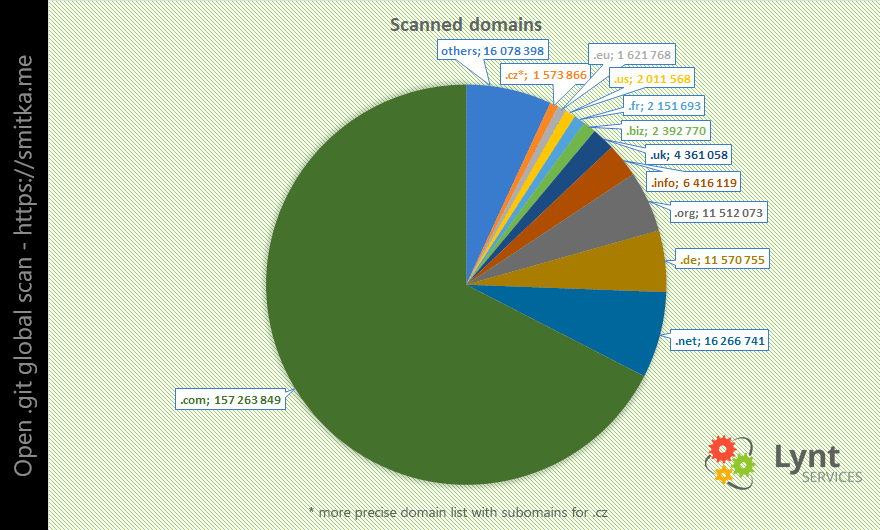
It was clear that it would be necessary to divide the task into multiple servers. So I split the list into blocks of 2 million domains. Then I made a mini PHP application to serve the blocks to the individual servers and record which server takes which block.
Very quickly it became obvious that the library Requests weren’t right for this task. The first problem was in timeouts – you are only able to set the connection timeout but not the data timeout – if the server opened a connection, but did not send any data, or sent it very slowly, then the thread was stuck (the examined static file was tiny, so the response should be quick). Within 10 to 20 minutes, a few thousand connections were frozen, and the scan became extremely slow. Update: Requests supports both timeouts, I had missed it in the documentation.
URLlib 3 library allows you to set both kinds of timeouts – so I tried to use it. The first minor problem was that it doesn’t provide you with the URL after redirects (I only counted the landing pages – a huge amount of domains are only for redirection). But after a while, I solved it (the code: retries.history[-1].redirect_location). Now the scan started to work more reliably, but it was still very slow, and I was very quickly out of RAM.
So, I decided to try the new (for me) asyncio library with aiohttp. This was a step in the right direction. I got 20 times faster scanning and a rapid reduction in memory consumption. There was a problem with weaker machines – they weren’t able to create 2,000,000 futures (tasks), so I divided the block into smaller parts according to the server’s capabilities (even the weak VPS can manage 100,000 futures). The scan resumed and another problem immediately appeared. I ran into the limit of open files in the Linux kernel, I raised this limit and the scan could finally start to run.
During this research, I very often encountered different tarpits (special servers that accepted the request, but didn’t return any data – their purpose is to slow down scanners like mine). A similar problem was with very slow servers. Geographic distance was often a problem, so I tried to sort out some geographic groups and manually run them from a nearby data center – e.g. the special server for Australia. All these problems multiplied in the global scan compared to the smaller local research I usually do, so I wasn’t able to completely prevent hang-ups. I also encountered various honeypots (fake servers that set up as decoys to attract and occupy scanners) that put me on different blacklists and sent abuse reports – complaints to the VPS providers that I had to deal with. Due to the risk of being blocked, I used several providers:
- Digital Ocean – we use them for many projects
- Linode – a big part of this particular scan ran from this provider – I appreciate the active work of their security team, they understand projects like this
- Hetzner – for testing, they offer good performace for the money
- BinaryLane – for scanning Australia
The whole scan ran for almost 4 weeks. Halfway through I decided to double the number of machines involved – the largest peak was 18 VPS + 4 physical servers. For a similar kind of tasks, it is especially important to have good connectivity, and more CPUs are also beneficial.
Why didn’t I use Amazon Lambda? This kind of big scan was new for me and I didn’t know what to expect, and I was worried about the service bill after scanning 🙂 In contrast, the VPS costs can be easily estimated – the whole scan cost around $250 (we already own the physical servers).
During the scan, I found 390,000 web pages with the open .git directory.
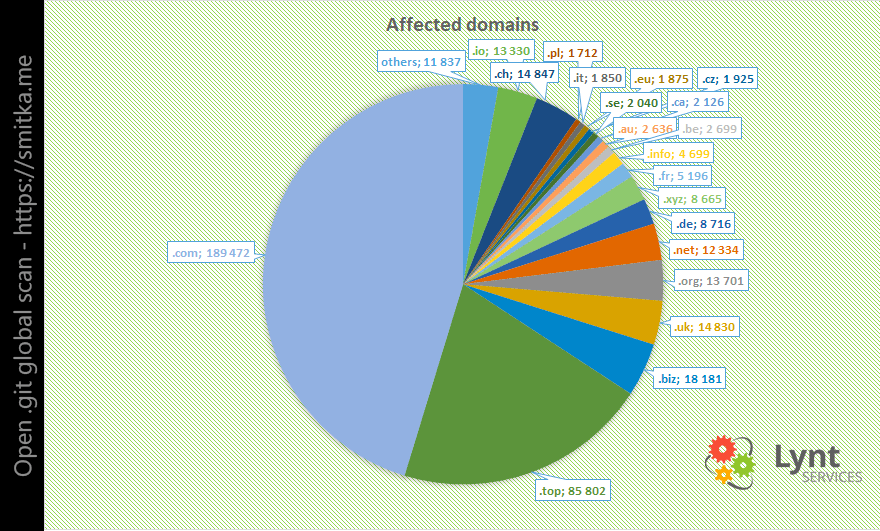
In the second part of the scan, I visited these pages again to find email contacts from the /.git/logs/HEAD file. There were a lot of invalid emails, but still, I got 290,000 emails tied up with different domains. They had to be further processed as many contacts were associated with multiple domains – some with more than 4,000. Of course, I didn’t want to send 4,000 email alerts to one person, so I aggregated the list by email address. I excluded the “machine” addresses of the servers, where there is a minimal chance that they will even be delivered or read. After these operations I got a list of 90,000 unique emails and started sending them a warning throughout an entire week. I prepared the landing page smitka.me with detailed information and mitigation, and referred people to it in the emails.
Around 18,000 emails weren’t delivered, because the recipient no longer exists or wasn’t real. According to the feedback, some of the emails were classified as spam even though they had scores of 10/10 in the tests at mail-tester.com – probably because of a large number of reported links.
After sending the emails, I exchanged about 300 additional messages with affected parties to clarify the issue. I have received almost 2,000 thank-you emails, 30 false positives, 2 scammer/spammer accusations, and 1 threat to call the Canadian police.
The main goal was accomplished. But there was an additional research task – to find out what technologies the affected sites use. So I launched the WAD tool on the affected sites list. WAD was complemented by the current Wappalyzer definitions (apps.json). Unfortunately, this tool is not well maintained – works properly only with Python 2 and doesn’t handle exceptions properly. I wasn’t able to feed it from the text file because the one exception would result in a crash the application. So I ran the scans individually using the GNU Parallel tool:
cat sites.txt | parallel --bar --tmpdir ./wad --files wad -u {} -f csv
For my work, I also use the great MobaXterm Session Management tool. I published some sample scripts from the scan on GitHub.
The results
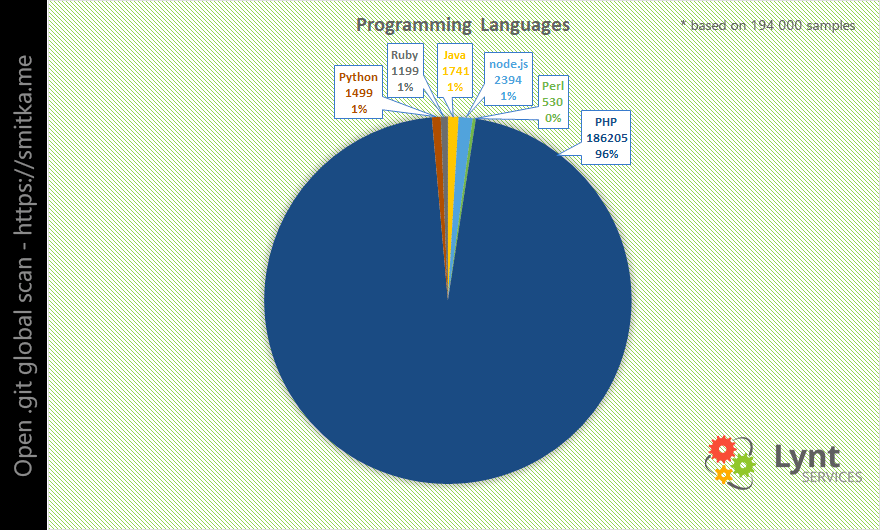
PHP is the most used programming language for the web, so it is obvious that most of affected sites use PHP.
It was very interesting to normalize these numbers according to the language market share (by W3techs):
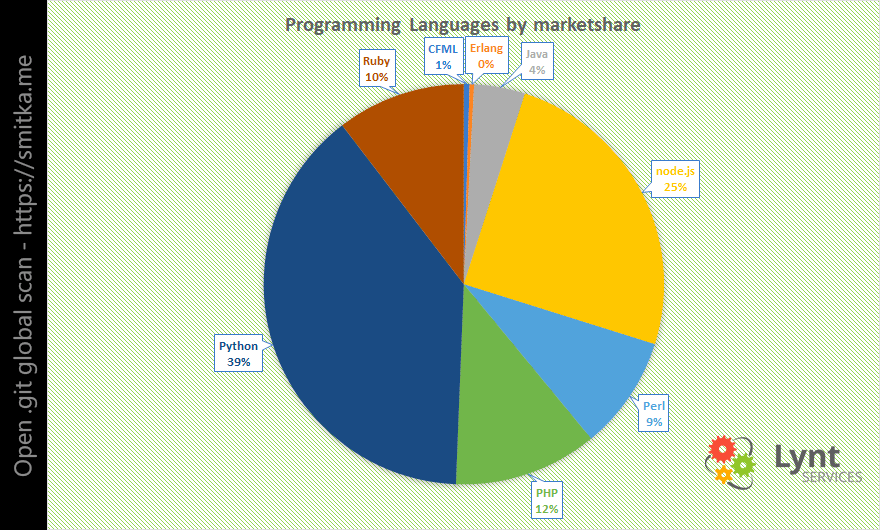
If all languages were used to the same extent, the worst situation would be among the Python developers, with PHP in third place.
I was curious which webservers and OS the affected servers use:
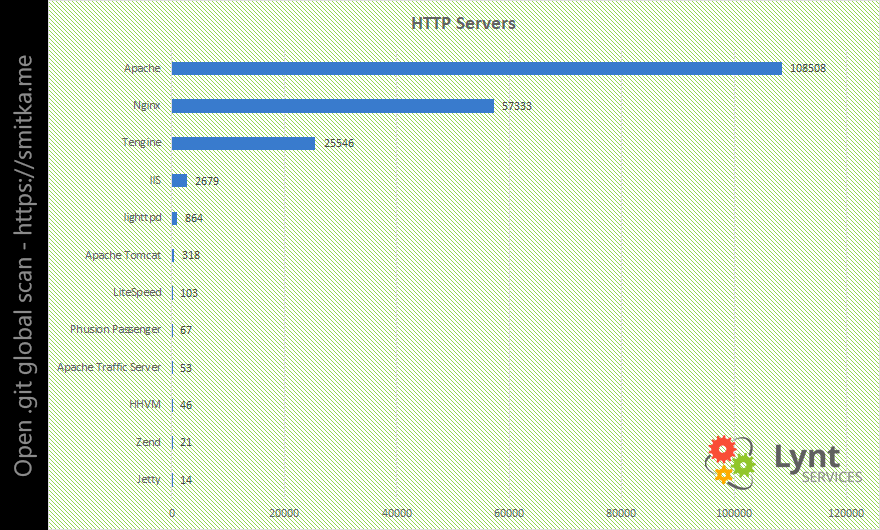
I was surprised with the large ratio of Tengine (it is a chinese fork of Nginx).
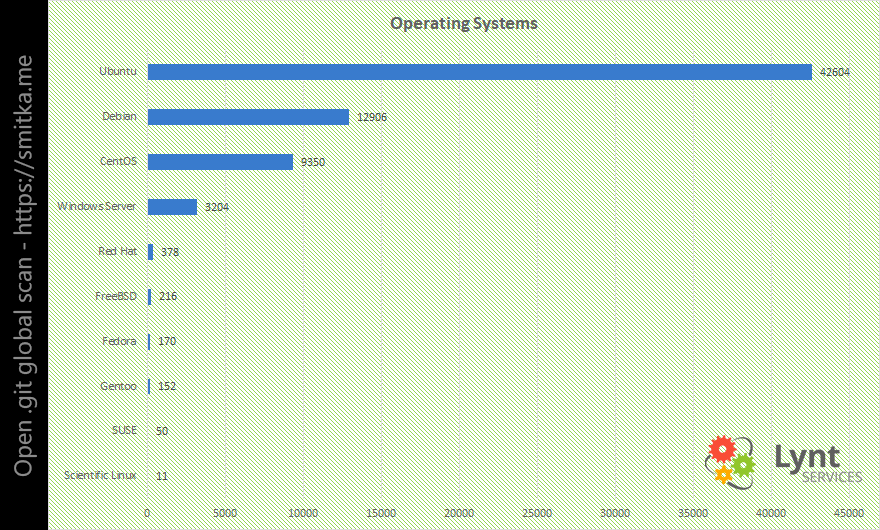
Ubuntu is the leading Linux distro. My favourite CentOS is in third place.
The last insight was focused on CMS, E-commerce solution, and App Frameworks.
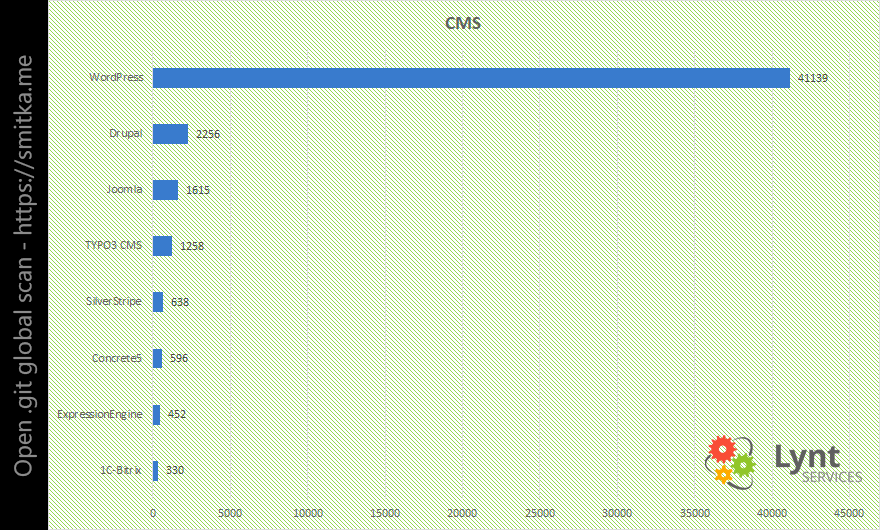
WordPress domitates in this category. Only about 12% of these WP sites use the latest minor versions with the latest security patches. It is because when WP finds the .git (or other VCS) directory, it disables automatic core updates. It works the same with Drupal and Joomla – the majority of these sites were the older versions.
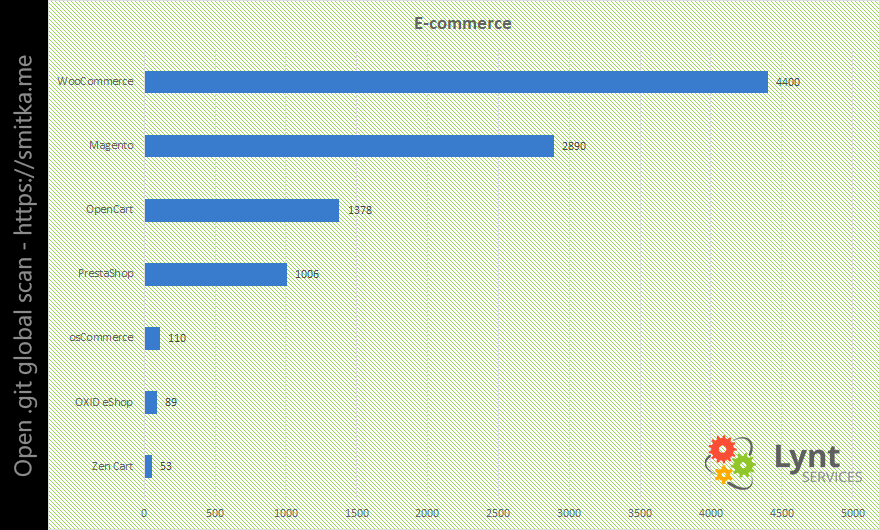
The situation is almost the same in the world of e-commerce. The WooCommerce WP plugin was found on the majority of these sites.
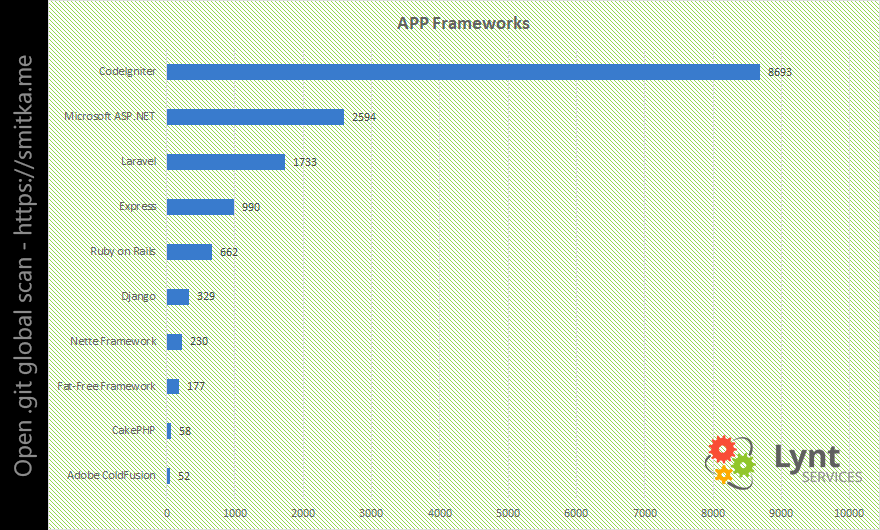
It can be hard to detect the application framework, lot’s of them are hiding their presence and it isn’t easy to detect them. But in some cases I was lucky. The most affected sites use CodeIgniter.
The plan is also to carry out the inspection after several weeks and attempt to re-contact the developers. The dataset will be much smaller, so I want to add two false positive reduction functions:
- check if the commit id is publicly available on GitHub
- check the index to see if the repository contains dynamic files
In the end, I would like to recommend to everyone that you watch what you upload to your website more carefully – it’s not just about system versions but also various temporary test scripts. It is also good to remember that things are changing – server configurations and team members, and what doesn’t seem like a problem today may be problem tomorrow.
As always, thank you, Paul, for the language corrections 😉