Rozlišuji 3 hlavní kategorie problémů:
- Bezpečnostní problémy – ty jsou samozřejmě nejzásadnější a často umožní do stránek vložit cizí kód nebo získat citlivé informace.
- Technické problémy – nějaká součást webu je špatně navržena a může se začít nepředvídatelně chovat; pro návštěvníka webu jsou tyto problémy často neviditelné
- Výkonnostní problémy – jednoduše: “Mám pomalý web”
Podívejme se nyní na jednotlivé kategorie problémů.
- 1 – Neošetřené uživatelské vstupy
- 2 – Správce souborů dostupný bez ověření oprávnění
- 3 – Libovolné rozesílání e-mailů
- 4 – Nepoužitelná stránka 404 Nenalezeno
- 5 – Množství zbytečných přesměrování
- 6 – Nezvládnuté stránkování
- 7 – Nepoužívání Expires hlaviček a komprese
- 8 – Neoptimalizované obrázky
- 9 – Velké množství statických souborů
- 10 – Vypnutý KeepAlive
Bezpečnost
Nutno podotknout, že poslední roky pozoruji v této oblasti značné zlepšení. Je to dáno především hojnějším využívání frameworků pro vývoj webových aplikací, jako je například Nette nebo Symphony. Výhodou použití takovýchto nástrojů je, že je v nich velká část běžných problémů vyřešena – například ošetření uživatelských vstupů pro různé kontexty (ukázkovým příkladem je šablonovací systém Latte v Nette frameworku). Začít psát vlastní systém bez použití nějakého podobného frameworku bych dnes určitě nedoporučil.
Pokud se přeci jen rozhodnete psát vlastní systém/framework na zelené louce, tak zbývá popřát jen hodně štěstí, v následujících letech ho budete potřebovat.
Již hotové prověřené redakční systémy také nejsou špatnou volbou – WordPress nebo Drupal již v základu velmi dobře vyřeší mnoho potenciálních problémů. První zmíněný je známý mnoha bezpečnostními problémy, ale ty v naprosté většině nebyly způsobeny systémem samotným, ale některým z doplňků třetích stran. Pokud jsou rozšíření dobře vybrána a systém je udržován aktuální (což je u všech Open Source řešení nutnost), tak úroveň bezpečnosti není špatná.
Chyby v rozšířených Open Source CMS systémech jsou poměrně rychle známé a rychle opraveny. O chybách ve vlastních řešeních na míru se často nikdo nedozví, a tak můžou v systémech přetrvávat velmi dlouho a ve výsledku mohou být následky mnohem horší.
Troufám si říci, že při korektním použití běžných frameworků a CMS je riziko chyb poměrně nízké.
Nebudu se zde zabývat problematikou šifrovaného spojení. Není to z důvodu, že by používaní nešifrovaných protokolů nebyl problém, ale proto, že by si tato problematika zasloužila vlastní článek. V rychlosti – proč používat šifrovanou komunikaci?
- je mnohem náročnější odposlechnout citlivé údaje uživatele
- je mnohem náročnější vaši stránku modifikovat po cestě a vložit do ní například nežádoucí kód
V době, kdy je k dispozici certifikační autorita Let’s Encrypt (12.4.2016 opustila beta stádium), už není ani cena certifikátu překážkou. Přesto zabezpečené spojení stále mnoho webů nepoužívá.
K problematice šifrovaného spojení naleznete asi nejvíce v přednáškách Michala Špačka.
Podívejme se tedy nyní na další časté problémy:
Problém č. 1 – Neošetřené uživatelské vstupy
Pravděpodobně nejčastější problémy jsou spojené s nedostatečným ošetřením uživatelských vstupů. Nejčastěji se setkávám se zranitelností typu XSS (Cross Site Scripting), kdy se na stránce podaří (často pomocí parametrů v URL) vykonat cizí JavaScriptový kód, nebo stránku jinak modifikovat.
Nejčastěji se jedná o vyhledávací, komentovací a jiné formuláře.
Častým místem, kde se tato chyba projeví, je výpis hledaného řetězce – např. pokud necháme vyhledat <script>alert(‘ahoj’)</script>, skript se vykoná v sekci s “Výsledky hledání výrazu”.
Hledaný řetězec se však nemusí vyskytovat jen v tomto výpisu, kde bývá správně ošetřen, ale často se nachází i například v kódech pro zaslání události do Google Analytics, nebo třeba prvcích hlavičky webu (title, meta tagy). Šikovnou úpravou hledaného výrazu se může podařit původní skript ukončit a vložit vlastní, nebo do meta hlavičky vložit “refresh” a přesměrovat návštěvníka na úplně cizí web.
Příklad v zasílání události do GTM (zde je časté vložení přímo URL z adresního řádku, která může obsahovat uživatelem předané parametry – není ani potřeba žádný formulář):
dataLayer.push({‘event’:’search’, ‘query’:’‘});alert(‘ahoj’);({‘a’:’a’});
Příklad v meta tagu description:
Častěji než je zdrávo se na stránce vyskytuje také různý zakomentovaný kód, který v sobě rovněž obsahuje modifikovatelné parametry. Útočný řetězec pak jednoduše komentář ukončí a přidá vlastní kód.
Při hledání těchto zranitelností vkládám do formulářů a URL adresy nějaký vlastní řetězec a následně ve vygenerovaném zdrojovém kódu hledám, kde se objevil, v jakých kontextech a zda jsou speciální znaky těchto kontextů správně ošetřené (převedené na entity, escapované, doplněné mezerami a podobně).
Druhým častým místem pro vznik této chyby je “paměť” formulářů. Často setkávám s tím, že lze formulářovým prvkům předat výchozí hodnoty z URL (případně z Cookies) i pro políčka, se kterými se původně pravděpodobně nepočítalo (např. pro různé hidden) a nejsou tak důkladně ošetřené.
Tuto chybu hledám tak, že jako URL parametry (nebo v Cookie, pokud bějaké vhodné existuje) vložím jména všech nalezených formulářových políček ve stránce a nastavím jim specifický řetězec. Následně ve zdrojovém kódu hledám, kde se řetězec objevil a jak byl ošetřen.
Může se zdát, že tento typ chyby není nebezpečný, protože využívá modifikované URL adresy, která se nikde běžně nevyskytuje (jedná se o tzv. non-persistent/reflected XSS). Nicméně útočník může odkaz publikovat třeba na jiném webu, v komentářích, nebo ho může zaslat e-mailem, a tím se odkaz stane “trvalým”. – praktické důsledky XSS
Ve stránkách, kde se vyskytují tyto chyby z neošetřených vstupů, někdy nalezneme i další typ nebezpečné zranitelnosti – SQL injection. Kvůli této zranitelnosti může útočník přímo modifikovat databázové dotazy a tím získat data z vaší databáze (například uživatelská jména a hesla). Naštěstí díky stále častějšímu používání různých abstraktních vrstev nad databází není tento problém tak rozšířený jako dříve.
Problémy často vznikají v případech, kdy vývojář přestane používat nástroje pro práci s databází, které framework/CMS nabízí, a začne skládat vlastní dotazy.
Útočné vektory pro zneužití SQL injection mohou být velmi složité. Již dlouho jsem se u modernějších stránek nesetkal s jednoduchými vektory typu zakomentování ověření hesla pomocí upraveného jména – např. admin” ; —
Setkávám se s možností výpisu informací z jiné tabulky:
clanek.php?id = 0 union select 1,2,heslo,4,login,6 from users
(funkce očekává že dotaz vrátí jeden řádek z databáze – ID nula pravděpodobně neexistuje a první část dotazu nevrátí nic, zde nastupuje union select, který při znalosti počtu sloupečků původního dotazu připojí výsledek úplně jiného dotazu).
Nejčastějším typem je však tzv. Blind SQL injection – nejsou přímo vypsány citlivé informace, ale je možné se databáze ptát na otázky s odpovědí ANO/NE (například “Je první písmenko hesla uživatele admin H?”). Z chování databáze pak lze tuto odpověď určit – při kladné odpovědi jsou vypsány všechny produkty, při negativní žádné / při kladné odpovědi dotaz trvá delší dobu než při negativní. Pomocí automatizovaných nástrojů lze takto z databáze vyčíst prakticky všechny informace.
Zde trochu odbočíme k výkonnostním problémům: špatně napsané SQL dotazy způsobují často také výkonností problémy. Setkal jsem se například s dotazem:
SELECT page_id FROM `product_pages` WHERE (product_id IN (SELECT id FROM `product` WHERE (status = ‘1’) AND ( product LIKE ‘x’)))
Tento dotaz se prováděl několik vteřin. Po přepsání s INNER JOIN se dotaz vykonával pouze několik milivteřin se stejným výsledkem
SELECT page_id FROM `product_pages` INNER JOIN product ON product_id = product.id AND (status = ‘1’) AND ( product LIKE ‘x’)
Jak si tedy uživatelské vstupy ohlídat, jestliže nepoužíváme nástroje, které je sami hlídají?
Ve vlastním kódu je nejjednodušší použít tzv. techniku izolátorů – slíbíte si, že s proměnnými, které jsou uživatelem nastavitelné, budete pracovat pouze v jedné části kódu – $_GET, $_POST, $_COOKIE, $_REQUEST (tu ani nedoporučuji používat), $_SERVER (ano, i některé proměnné zde může uživatel ovlivnit) + samozřejmě některé funkce, které přímo vracejí jejich hodnoty.
V této vybrané části kódu si všechny proměnné příslušně ošetříte a přeřadíte je do nových proměnných, se kterými budete dále ve zbytku kódu pracovat.
Nebo ještě lépe – vytvoříte si vlastní funkce, které příslušné proměnné budou vyčítat a rovnou ošetřovat dle kontextu, a použijete pouze ty.
např. zjednodušeně:
function get_to_html($string) {
return htmlspecialchars($string, ENT_QUOTES, 'UTF-8');
}
Více o problematice escapování různých kontextů na PHPfashion.com.
Pro escapování v HTML lze také použít velmi propracovanou knihovnu HTML Purifier (pracuje s HTML výstupem, neřeší SQLi).
Pokud použijete izolátory, lze pak jednoduše prohledáním kódu zkontrolovat, že se proměnné $_ nacházejí pouze ve vybrané části kódu.
Lepší cestou je samozřejmě použití frameworku, který toto vše již ošetřuje. Stále vzniká nezanedbatelné množství webů, které je nepoužívají, a na tvůrci tak leží větší zodpovědnost, aby si vše sám ohlídal.
Problém č. 2 – Správce souborů dostupný bez ověření oprávnění
Moderní administrace často obsahují správce souborů, přes kterého může uživatel nahrávat soubory (především obrázky). Tento správce je často řešen jako samostatné rozšíření některého z WYSIWYG editorů, jako je TinyMCE nebo CKeditor. V samotném editoru, který je sám o sobě většinou neškodný, přibude tlačítko “Vybrat obrázek na serveru”, které spustí správce s možností modifikace souborů.
Řetězec vypadá zdánlivě takto:
Uživatel => Ověření pro vstup do administrace => stránka s wysiwyg editorem => správce souborů
Vzhledem k tomu, že správce souborů bývá samostatná komponenta, může řetězec být ve skutečnosti mnohem jednodušší
Uživatel => správce souborů
Při hledání tohoto problému většinou zkouším několik možností:
- zkusím přímo jeho adresu například www.example.com/filemenager (často používaná v dokumentacích správcům souborů),
- prohlédnu javascripty na přihlašovací stránce administrace, zda nenaleznu zmínky o WYSIWYG editoru nebo file manageru,
- z umístění javascriptů se snažím odhadnout cestu, kde by mohl být schovaný WYSIWYG, a zkusím ho inicializovat/nalézt jeho zapomenutou dokumentaci s příklady
Pokud editor/správce naleznu, nic nebrání jeho otevření a manipulaci se soubory na serveru.
Možná někdo může namítnout, že se nejedná o příliš zásadní problém, protože správci souborů jsou často omezeni jen na nahrávání obrázků a nahráním obrázku nelze způsobit příliš škody.
Mějme na paměti, že problémy mají tendenci se řetězit.
Může být například chyba v samotném správci souborů, kdy se podaří filtr, který brání nahrání jiných souborů než obrázků, obejít. Častá je kontrola přípony nahraného souboru a zároveň možnost soubor přejmenovat – stačí nahrát soubor evil.php.jpg a následně jej přejmenovat pouze na evil.php. Ale i samotná manipulace s obrázky může přinést velké problémy. Co když třeba dojde ke smazání obrázkového tlačítka “Vložit do košíku”, které následně není vidět? Je možné, že vy ho máte v cache prohlížeče, takže problém nepozorujete, jen objednávky najednou přestaly chodit. Nebo lze nahráním obrázků vaši společnost poškodit úplně jinak – co když útočník nahraje na web nějaké kompromitující materiály? Nelegální filmy, falešné smlouvy, …
Osobně mne překvapilo, na kolika různých webových stránkách jsem na podobný problém narazil.
Je třeba se vždy ujistit, že je souborový manažer pevně svázán s autorizačním mechanizmem stránek.
Problém č. 3 – Libovolné rozesílání e-mailů
Kontaktní formuláře jsou součástí mnoha stránek. Někdy se však nepodaří tuto komponentu příliš dobře zpracovat a obsahuje například skryté políčko, které nastavuje doručovací adresu. Změnou jeho hodnoty lze pak e-mail odeslat prakticky komukoliv.
Jaké nebezpečí se v tom skrývá?
Pokud formulář dovoluje i změnu textu emailu, mohou ho útočníci využít pro rozesílání spamu. Pokud je text neměnný, stále hrozí, že jej někdo využije pro rozeslání ohromného počtu emailů za účelem dostání serveru/domény na blacklisty.
Zvláštní kapitolu tvoří formuláře “Pošli odkaz na tuto stránku svému kamarádovi emailem”, kdy formulář obsahuje nejen cílovou, ale i zdrojovou adresu. Problém je v tom, že mnoho domén má pomocí SPF (sender policy framework) nastaveno, z jakých serverů může e-mail, který onu doménu používá, odcházet. Ve výsledku tedy tento typ formulářů pro svůj původní účel spíše nefunguje než funguje.
Co s tím tedy udělat?
Hlavní pravidlo je nenechat uživatele manipulovat s informacemi odkud a kam má být e-mail poslán. Přiznávám, že tento krok může být velmi obtížný, protože samozřejmě lze použít například registrační formulář a poslat potvrzení o registraci na libovolnou adresu. Důležité však je, aby tento postup nešel jednoduše provádět automaticky. Tomu lze zabránit například používáním CSRF tokenu – jedná se vygenerovaný “klíč” pro každý formulář a jeho následnou kontrolu před zpracováním. Pro odeslání formuláře je tedy třeba, aby ho vytvořil váš web, a není možné se napojit přímo na odesílací skript.
Velmi jednoduše lze formuláře takto ošetřit například v Nette – $form->addProtection();
Technické problémy
Jako technické problémy zde označuji to, že se stránky dostanou do stavu, se kterým se nepočítalo, nebo provádějí operace, které nejsou potřeba.
Technických problémů může být ohromné množství od jednoduchého odkazu na zdroj, který neexistuje, až po chyby způsobující přetížení stroje. Je těžké je nějakým rozumným způsobem rozdělit, pokusil jsem se však alespoň popsat několik běžných problémů a jejich důsledky.
Problém č. 4 – Nepoužitelná stránka 404 Nenalezeno
Může se zdát, že nedokonalá chybová stránka “404 Nenalezeno” nepředstavuje zásadní problém. Možná jste přesvědčení, že ani žádné takové stránky na vašem webu nejsou.
Jste si však například jisti, že neexistovaly předchozí verze stránek s jinou strukturou URL? V takovém případě můžou na váš web vést staré odkazy na aktuálně neexistující stránky. U e-shopů často neexistující stránky vznikají v případě, že je produkt stažen z prodeje a stránka tak zmizí.
Může se také stát, že v odkazu, který na vás vytvoří někdo jiný, schází několik posledních znaků, nebo naopak přibývá mezera – a odkaz na neexistující stránku je na světě.
Pokud uživatel přijde na neexistující stránku a zobrazí se mu základní bílá chybová stránka serveru, nemá žádnou šanci pokračovat dál a web s velkou pravděpodobností opustí. Pokud stránku zpracujete v designu webu, kde je funkční menu a další prvky stránek, může uživatel v užívání vašeho webu dále pokračovat.
Samozřejmě pro mnohé uživatele není problém si část URL z adresního řádku odmazat a dostat se na hlavní stránku. Neumí to však zdaleka všichni a je také otázka, proč by to měli ti znalí dělat – zkuste si pohodlně odmazat kus URL na mobilním zařízení.
Nejlepší cesta je samozřejmě snažit se neexistujícím stránkám vyvarovat například jejich přesměrováním na alternativní stránku se stejným/souvisejícím obsahem. Pokud máte opravdu dobrý systém, tak by měl být schopen návštěvníkovi i sám doporučit vhodný obsah vašeho webu:
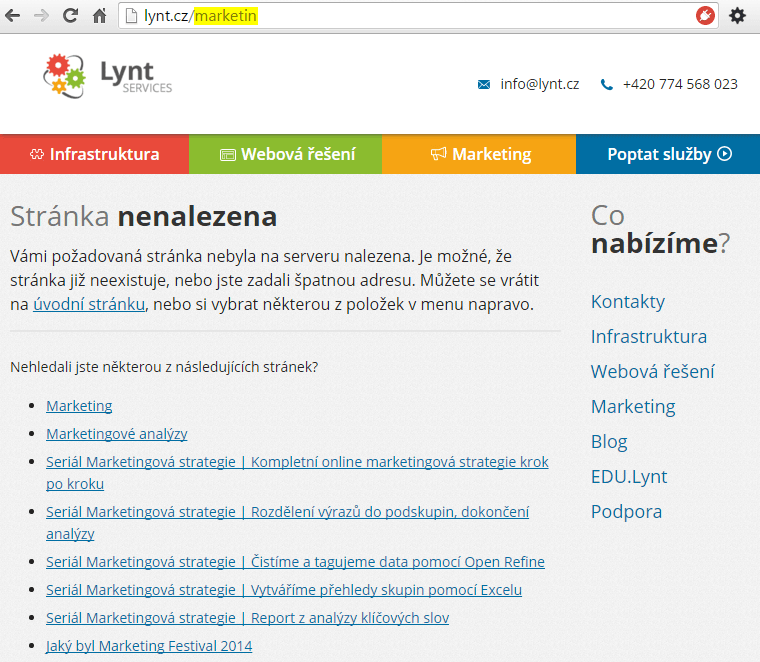
Dalším vážným problémem, který vaše stránka 404 může mít, je to, že nevrací stavový kód 404, ale například 200. Tento problém může způsobit problémy především vyhledávačům. Ty mohou indexovat neexistující stránky, čímž nezískají žádný zajímavý obsah, budou při tom muset vykonat mnoho práce navíc a nebudou váš web mít rády. Nepříjemností, která z toho plyne, je, že vyhledávače mohou vaše návštěvníky posílat na neexistující stránky. Nejhorší na tom je, že se o těchto problémech ani nedozvíte.
Dobrým řešením rozhodně také není přesměrovat všechny chyby na hlavní stránku.
Jak na chybovou stránku:
Zkuste vyvolat chybu – např. zadáním neexistující adresy http://vas-web/neexistuji-ale-okolni-svet-ano
Jste schopni pokračovat dále na svůj web? Pokud ano, tak je to dobře. Jesltiže byl navíc doporučen relevantní obsah, tak je to výborně. Pokud se zobrazila nic neříkající stránka, je to první bod k opravě.
Prohlédněte si požadavek např. v developer konzoli prohlížeče (Chrome – CTRL+SHIFT+J) – vidíte zde informaci o chybě 404? Pokud ano, tak je to v pořádku. Pokud ne, přepněte se na panel Network, zkuste stránku znovu načíst, prozkoumejte, jaký kód vrací, a následně zajistěte, aby byl vždy 404.
Prověřte svůj web nástrojem Xenu nebo Screaming frog, zda neobsahuje odkazy na neexistující stránky. Případné špatné odkazy opravte. Tuto kontrolu provádějte pravidelně.
Projděte si report v Google Developer console, zda vyhledávač nezná neexistující stránky (protože na ně například někdo odkazuje). Toto opět dělejte pravidelně.
Problém č. 5 – Množství zbytečných přesměrování
Obrázek za tisíc slov:
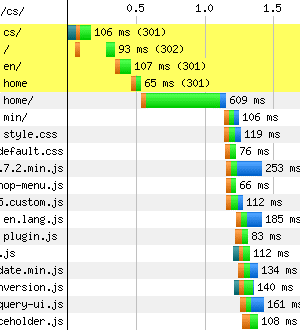
Půl vteřiny bylo vyčerpáno jen na řešení přesměrování.
Zbytečná přesměrování zpomalují webové stránky a přidělávají práci indexovacím robotům.
Nejčastěji k podobným přesměrováním dochází v následujících případech:
- z adresy s WWW na adresu bez WWW (nebo obráceně) – což je správné! Je potřeba si však ohlídat, aby na webu byly používány vždy odkazy v tom správném tvaru – setkávám se s weby, kde například redakční systém generuje odkazy s www, ale stránky používají doménu bez www a vše je na tuto variantu přesměrováno.
- přesměrování z http na https (opět správně!) – pokud provozujete web se zabezpečeným protokolem HTTPS, zkontrolujte, že i vaše odkazy v rámci webu odkazují na tento protokol. Například redakční systém WordPress tvoří absolutní odkazy, které se při změně protokolu automaticky nezmění.
- kanonizace koncového lomítka – mnoho redakčních systémů předpokládá adresy s koncovým lomítkem – http://vasweb/blog/. Toto je dobré respektovat při odkazování – pokud vytvoříme odkaz ve tvaru pouze http://vasweb/blog, dojde ke zbytečnému přesměrování. Pokud váš systém toto dělá, je vhodné koncové lomítko hlídat již na straně serveru a přesměrovávat ještě dříve než požadavek spustí skripty redakčního systému.
- přesměrování defaultního jazyka – často je příznak lokalizace proveden jako “podsložka” – http://vasweb/cs, ale defaultní jazyk bývá bez tohoto příznaku. Běžně se setkávám s tím, že jsou všechny odkazy vytvořeny s příznakem jazyka a každá stránka je tak přesměrována. Někdy tomu bývá i naopak – všechna URL mají mít příznak a odkazy jsou tvořeny bez něj. To se často stává, když byla lokalizace dodána až dodatečně a obsah je plný odkazů bez příznaku, které jsou následně přesměrovány na variantu s příznakem.
- přesměrování z nehezké URL na hezkou – opět jde o záležitost redakčního systému, kdy jsou v odkazech použity základní URL systému a následně přesměrovány na hezkou, chcete-li na “SEO”, variantu. Například u Drupal webů lze často vidět přesměrování typu /node/1044 => /pekny-clanek.
Obecně platí, že je potřeba určit si výchozí tvar odkazů (nebo se přizpůsobit tomu co nabízí CMS) a toho se vždy držet – při tvorbě obsahu i budování zpětných odkazů.
Doporučuji nechat si opět zkontrolovat webové stránky nástrojem Xenu nebo Screaming frog a přezkoumat, zda jsou nalezená přesměrování 301/302 opravdu nutná.
Problém č. 6 – Nezvládnuté stránkování
Udělat správné stránkování je mnohem náročnější než by se mohlo zdát. Je potřeba si ohlídat především meze, protože nechceme, aby se návštěvník dostal na stranu nula nebo na stranu milión.
Špatně nastavené meze mohou opět vést k indexaci mnoha zbytečných stránek. Několikrát jsem se setkal i se špatně vypočítaným stránkováním a část posledních stránek byla prázdná.
SEO konzultantům se často nelíbí, že je první stránka dostupná na více adresách, např. http://vasweb/clanky a http://vasweb/clanky?strana=1, což mohou vyhledávače brát jako duplicitní obsah a přikládat mu nižší hodnotu.
Osobně jsem pro to, aby stránkovaný obsah nebyl indexován (to lze zařídit pomocí <meta name=”robots” content=”noindex,follow“>), protože jde až o samotný obsah, na který se ze stránkovaného výpisu dostaneme. Výpis samotný většinou nenese žádné zajímavé informace (maximálně nějaký úvodní text na první stránce – v tom případě samozřejmě první stránku indexovat) a pozice jednotlivých položek se časem mění. Pokud by už vyhledávač návštěvníka zavedl například na 10. stránku, kde se požadovaný obsah v době indexace vyskytoval, aktuální stav může být odlišný a návštěvník potřebnou informaci nenajde.
Problémem může být také ohromné množství stránek bez možnosti jiné navigace. Pokud máte ve stránkovači více než cca 30 stránek, zamyslete se nad tím, zda by návštěvník někdy náhodou nepotřeboval přejít na konkrétní stránku. Dobré cvičení je si to vyzkoušet i na mobilním zařízení – třeba zjistíte, že šipky pro přechod na další podstránku jsou tak miniaturní, že je nedokážete přesně stisknout.
Starší článek z roku 2007 na SmashingMagazine.com o tom, jak by mělo stránkování vypadat. Aktuálnější článek v češtině naleznete na JeČas.cz.
Výkon
Rozhodně nejčastěji se setkávám s různými výkonnostními problémy webů. Je mnoho příčin, které je mohou způsobovat – například již zmíněné nevhodně napsané SQL dotazy, nebo nepoužívání OPcode cache. To jsou však problémy, které na při pohledu z vnější nelze rozpoznat. Je zde však několik problémů, které rozpoznatelné jsou a jejichž náprava není složitá.
Odhalit výkonností problémy mohou pomoci nástroje jako například GTmetrix, který se vaše stránky pokusí načít a nalezne běžné problémy podle Google Page Speed a Yahoo Yslow.
Problém č. 7 – Nepoužívání Expires hlaviček a komprese
Zřejmě nejčastějším problémen, se kterým se setkávám, je nepoužívání Expires hlaviček pro statické soubory. Tyto hlavičky určují, jak se bude prohlížeč chovat ke zdrojům, které se často nemění (jak často měníte logo?). Konkrétně se jedná o hlavičky Cache-Control a Expires. První určuje, jak se ke zdroji mají chovat různé druhy cachovacích systémů. Více informací naleznete na JakPsátWeb.
K článku bych ještě doplnil hodnotu private, která zabrání cachování na sdílených cache (např. firemních proxy serverech), ale povolí použít cache uživatelova prohlížeče.
Hlavička Expires udává, kdy bude zdroj považován za zastaralý a bude ho třeba znova stáhnout.
Pokud tyto hlavičky nejsou nastaveny, může se stát, že bude potřeba všechny zdroje znovu stáhnout při dalším načtení stránky. Dříve tomu tak bylo prakticky doslovně. V boji o rychlost přišly prohlížeče s metodami, jak cachování na straně klienta provádět i bez těchto hlaviček, aby dokázaly překonat nástrahy, které jim leniví tvůrci stránek přichystali.
Například v dokumentaci Firefoxu nalezneme následující vysvětlení jejich heuristického algoritmu:
… if neither header is present, then we look for a “Last-Modified” header. If this header is present, then the cache’s freshness lifetime is equal to the value of the “Date” header minus the value of the “Last-modified” header divided by 10.
Pokud tedy není nalezena příslušná hlavička, použije se rozdíl aktuálního data a data v hlavičce Last-Modified vydělený 10 – pokud je soubor starý 20 dní, bude považován za čerstvý další 2 dny.
Ostatní prohlížeče však mohou používat jiné metody.
Nechat rozhodovat prohlížeč za tvůrce určitě není ideální stav. V naprosté většině případů ke změně obrázku již nikdy nedojde, změny stylů a javascriptů lze ošetřit parametrem s revizí. Problémem je i nový obsah, který má následně vypočítanou dobu expirace velmi krátkou.
Pro nastavení Expires hlaviček v http serveru Apache stačí mít nainstalován modul mod_expires a následně v .htaccess nastavit například:
<ifmodule mod_expires.c>
<filesmatch "\.(?i:gif|jpe?g|png|js|css|swf|ico|woff)$"="">
ExpiresActive on
ExpiresDefault "access plus 365 days"
</filesmatch>
</ifmodule>
Pokud máte dobře nastaveny mime typy, lze pro ně použít direktivu ExpiresByType:
ExpiresByType image/jpg "access plus 1 year"
Pokud se již bavíme o konfiguraci Apache, je vhodné zmínit ještě zapnutí GZIP komprese pro textové soubory, a tím rapidně snížit jejich přenášený objem. Velmi často vídám nepoužívání komprese u webů, které nemají ani nastaveny Expires hlavičky. K používání komprese je třeba mod_deflate a konfigurace do .htaccess podobná této:
<ifmodule mod_deflate.c>
AddOutputFilterByType DEFLATE text/css application/x-javascript text/x-component text/html text/richtext image/svg+xml text/plain text/xsd text/xsl text/xml image/x-icon application/javascript
</ifmodule>
V konfiguraci jsme narazili na zajímavý termín DEFLATE, který v minulosti způsobil spousty zmatků. Kompresi v HTTP protokolu lze typicky provádět 2 metodami – gzip a deflate. Deflate je samotný kompresní algoritmus, který je implemetován v několika formátech.-Jedním z nich je právě GZIP, který ke komprimovaným datům dodává svou hlavičku a kontrolní součet. Druhým formátem je ZLIB, který opět využívá Deflate a také mu přidává svou hlavičku a kontrolní součet. Přidaná data jsou o něco menší než u GZIP a výpočet je o něco rychlejší. Bohužel se, trochu nešťastně, pojmenovala komprese pomocí ZLIB po svém základním algoritmu – tedy deflate. To způsobilo nejednoznačnost a některé prohlížeče (i HTTP servery) si pod pojmem “kompresí pomocí deflate” představovaly kompresi pomocí ZLIB a jiné kompresi pomocí čistého algoritmu deflate bez žádných přidaných hlaviček a kontrolních součtů. To mělo za následek častou nefunkčnost webů v různých prohlížečích a preferenci jednoznačného formátu GZIP, který je dnes téměř výhradně používán.
Můžeme se však setkat i s dalšími metodami – Google se rozhodl gzip kompresi vylepšit a vyvinul algoritmus Zopfli. Tento algoritmus je kompatibilní s GZIP (jedná se pouze o postup komprese, dekomprese je možná pomocí stávajících nástrojů) a úspory dosahuje tak, že předem dělá analýzu dat, aby mohl lépe nastavit kompresi. Jedná se tak zatím o nejefektivnější kompresi využívající deflate. U toho se však Google nezastavil. Dalším z algoritmů je SDCH (“sandwich” – Shared Dictionary Compression for HTTP). Ten je založen na principu, že se komunikující strany předem domluví na určitém slovníku, který pak využívají, a místo samotných dat se tak ve vybraných případech bude přenášet pouze odkaz do slovníku. Nejaktuálnějším počinem Google je algoritmus Brotli, který využívá trik, že je distribuován již se základním slovníkem 13 504 frází, které se na webech běžně vyskytují. Brotli dosahuje o 25 % lepšího kompresního poměru oproti Zopfli. Tento algoritmus se postupně dostává i do dalších moderních prohlížečů (Firefox má podporu od verze 44 v Chrome a Opeře je potřeba jej aktuálně povolit: chrome://flags#enable-brotli). Ze strany serverů není podpora zatím veliká, k dispozici je neoficiální modul přímo od Google do webového serveru Nginx. V Apache je možné prozatím použít pouze staticky předkomprimované soubory.
Problém č. 8 – Neoptimalizované obrázky
Dalším problémem, se kterým se setkávám opravdu velmi často, jsou neoptimalizované obrázky, nebo použití pro daný účel nevhodných formátů. Nejedná se o úsporu několika jednotek kB, ale stovek kB a v některých případech i několika MB. Často jsou také načítány mnohem rozměrnější obrázky, než jsou reálně zobrazovány (nebavím se zde o technice použití několikanásobně většího obrázku ve velmi nízké kvalitě a jeho zmenšení v prohlížeči). I při zobrazování obrázků v plné velikosti je vhodné myslet na reálné rozměry monitorů – obrázek 4500×3000 stejně téměř nikdo rozumně nezobrazí.
Nejčastější problém je v použití 24 bitových PNG obrázků v případech, kdy to není potřeba. Častým důvodem je použití alfa kanálu. Alfa kanál lze ale použít i u 8 bitových PNG, jen starší verze Photoshopu jej neuměly vytvořit, proto jej téměř nikdo nepoužívá. Konverzi 24 bitového PNG můžete provést například pomocí skvělého online nástroje TinyPNG.
TinyPNG vám pomůže i s JPG obrázky, které jsou často nahrávány ve zbytečně vysoké kvalitě. Pro běžné JPG obrázky je nastavení kvality kolem 75 dostatečné, v případě exportu z Photoshopu kolem 60. Důležitost velikosti obrázků si uvědomují i tvůrci WordPress a tak v poslední verzi 4.5 došlo ke snížení výchozí kvality miniatur z 90 na 82. Tato hodnota je samozřejmě uživatelsky nastavitelná a osobně si myslím, že další lehké snížení neuškodí.
Volba vhodného formátu je zásadní. Používání PNG pro fotografie je zbytečné plýtvání místem, JPG pro drobnou webovou grafiku zase zbytečně degraduje kvalitu. Pro zmíněnou drobnou webovou grafiku může být vhodné použít formát SVG, který je již dobře podporovaný. Obrázkové fonty také mohou svůj účel dobře plnit. Nejpoužívanější je FontAwesome, který není zrovna malý (70-80 kB), ale je velká šance, že jej návštěvník již bude mít v cache. Od stejného tvůrce je dostupná služba FortAwesome, kde si můžete navolit pouze ty ikonky, které potřebujete.
Setkal jsem se i s použitím animovaných gifů pro videa (velká na celou šíři stránky). Účelem bylo umožnit uživatelům se staršími verzemi prohlížečů vychutnat si grafické efekty. Výsledkem však bylo stahování několika desítek MB pro každého uživatele… Volba formátu zde byla velmi nešťastná. Myslím, že i uživatel staršího prohlížeče (pravděpodobně tedy i staršího PC) by více ocenil, kdyby se stránka načetla rychle a šla používat i bez náročných grafických efektů.
Můj názor je, že je nejvhodnější částečně ignorovat starší prohlížeče – neřešit přesné grafické zobrazení a pouze zajistit, aby v nich byl dostupný užitečný obsah. Ušetříte spousty problémů jak sami sobě, tak i většině uživatelů.
Dříve zmíněné malé obrázkové ikonky mohou být problémem v případě, že jich je velké množství. Samotné HTTP hlavičky zabírají průměrně kolem 0,5 – 1 kB. Pro stažení malinké ikonky, která má pár stovek B, je tak stahováno mnohem větší množství dat. Samotné vyjednání spojení se serverem také nějakou dobu trvá, a tak může velké množství malých obrázků velmi zpomalit načítání stránky. Jedním řešením tohoto problému je sloučení více obrázků do jednoho – ušetří se tak drahocenná spojení a mnoho zbytečných dat ve formě HTTP hlaviček. Tato technika se jmenuje CSS sprites a pro vytvoření sloučených obrázků můžete použít například online nástroj SpriteGen.
Dalším řešením tohoto problému je použití nového protokolu HTTP/2, který umí větší množství zdrojů najednou načítat mnohem lépe a bez nutnosti používání CSS sprites. Dlouho před HTTP/2 bylo možné využívat protokol SPDY od Google, který funguje velmi podobně, nicméně je podporován pouze v prohlížečích od této společnosti. Hlavní výhodou HTTP/2 je tak fakt, že se na tomto standardu dohodli všichni tvůrci majoritních prohlížečů. Jak funguje tento protokol si můžete přečíst na Root.cz.
Pokud se jedná o dlouhou stránku, kde je větší množství obrázků, je možné použít tzv. Lazy Loading pomocí JavaScriptu – obrázky se postupně načítají chvilku předtím, než k nim uživatel doscrolluje.
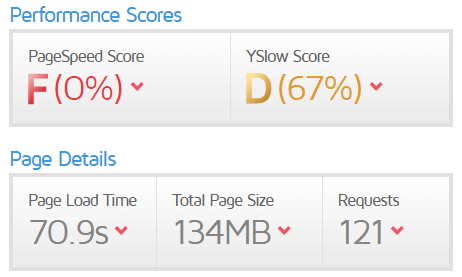
Problém č. 9 – Velké množství statických souborů
Problematiku velkého počtu obrázků jsme již probrali, to samé však platí pro JavaScripty a CSS. Velký počet různých knihoven web zbytečně brzdí.
Náprava je podobná jako u obrázků – minifikace a sloučení. Proč stahovat 10 menších souborů, když mohu stáhnout jeden větší najednou? Vzhledem k tomu, že jsou zmíněné soubory textové, je jejich kombinace mnohem jednodušší. Je pouze potřeba si dát pozor na jejich pořadí.
Minifikací se u CSS odstraní především nepotřebné mezery a zkrátí různé zápisy. Běžně se dá minifikací u CSS souboru ušetřit 30 – 40 % velikosti souboru. Minifikace JavaScriptu dále většinou nahrazuje jména funkcí a proměnných za kratší a dosahuje tak ještě lepších výsledků – často přes 50 %.
Provést minifikaci i zkombinování více souborů můžete například online nástrojem Refresh-SF. V našich projektech probíhá tato činnost automaticky při deploymentu pomocí Capistrano.
Často se setkávám s použitím zbytečně velkých knihoven, ze kterých je využita jen velmi malá část. Setkal jsem se s mnoha weby, které používaly knihovnu jQuery UI (minifikovaná verze má zhruba 250 kB, mnohokrát jsem však viděl i tu neminifikovanou, která je 2x větší), aby z ní použily například date-picker, nebo taby. Pro podobné funkce je možné vybrat mnoho alternativ, které jsou mnohem menší. Nezřídka se také stává, že jsou některé knihovny načteny vícekrát. Typicky se tak děje například s knihovnou jQuery – ta je například použita již v rámci redakčního systému a dále v doplňkových skriptech různých služeb. Několikanásobné použití jQuery můžeme vidět u redakčního systému WordPress při používání nevhodně napsaných rozšíření. -Ve WP je jQuery použito v takzvaném bezkonfliktním módu – nelze jej tak volat jednoduše pomocí $, ale je potřeba použít proměnnou jQuery. Mnoho hotových skriptů s tím však nepočítá, a tak nefungují. Řešení je však jednoduché. Stačí kód obalit do funkce, která řekne, že dolar znamená jQuery:
(function( $ ) {
$(function() {
//zde je možné již používat kód s dolary
});
})(jQuery);
nebo
jQuery( document ).ready(function( $ ) {
//tady už kód s dolary bude také fungovat
});
CSS a JS souborům velmi prospěje komprese, kterou jsem zmiňoval v bodu 7.
Problém č. 10 – Vypnutý KeepAlive
KeepAlive je technika, která umožňuje ušetřit počet navázání spojení klienta se serverem. Jde o to, že v základu každý požadavek na server musí otevřít TCP spojení, a to nějakou dobu trvá. KeepAlive nechává spojení nějakou dobu otevřená, tím pádem je přes ně možné vyřídit několik požadavků a ušetří se tím režie spojená s navazováním spojení.
A jak velká tato úspora může být?
Při navazování TCP spojení se děje takzvaný třícestný handshake – klient pošle požadavek SYN, server odpoví SYN, ACK a klient tuto odpověď potvrdí ACK. Následně mohou začít proudit opravdové požadavky na data. Prakticky tedy před posláním dat dojde dvakrát k výměně packetů tam a zpět. Zde záleží na latenci (zjistíte pomocí nástroje ping) mezi klientem a serverem.
Pro vykonání dalších požadavků je také potřeba spojení zavřít podobnou sekvencí (místo SYN se posílá FIN), pouze není třeba čekat na druhou odpověď.
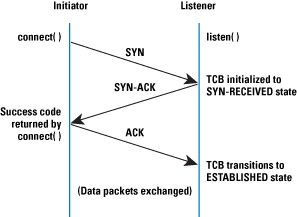
V mém případě je latence kolem 7ms, samotný začátek komunikace tedy bude trvat cca 14 ms (zjednodušeně řečeno) + 7ms pro ukončení komunikace pro každý požadavek vyslaný na server (obrázek, CSS, JavaScript).
Pokud vezmeme v potaz předchozí problémy, kdy stránka bude používat například 150 statických zdrojů a to, že prohlížeč umí obsluhovat několik paralelních požadavků najednou (běžně 6 i více, ale ne vždy lze všechny najednou provést – počítejme tedy 5), a použití mobilní připojení, kde může být latence 300 ms i více, tak jen vyjednávání spojení spotřebuje 3x300x150/5 ms = 27 vteřin. Toto platí při vypnutém KeepAlive. Pokud je zapnutý, lze na jedno spojení zpracovat desítky požadavků. V našem modelovém případě by tedy mohl prohlížeč obsloužit všechny požadavky najednou paralelně a doba spotřebovaná na vyjednávání spojení by byla pouze 0,6 vteřiny.
Na většině serverů je tato technika povolená. Existují však důvody proč ji vypnout. Nevýhodou KeepAlive je to, že je nutné uchovávat spojení otevřená, i když zrovna nejsou potřeba, a to spotřebovává RAM. Pro velmi navštěvované servery může KeepAlive spotřebovat velké množství paměti, a je proto vypínán. Pokud je KeepAlive zapnutý na velmi navštěvovaném serveru, může způsobit pár Apache. Takové servery však většinou mají vyřešen počet požadavků, používají pokročilejší infrastrukturu a statické soubory mají umístěné na CDN. S vypnutým KeepAlive se však setkávám i v případě menších webů, které načítají desítky souborů a KeepAlive je vypnutý. V těchto případech se jedná o poměrně velké zdržení.
Běžné nastavení pro Apache (defaultně je KeepAlive zapnutý) může vypadat například takto:
KeepAlive on
MaxKeepAliveRequests 50
KeepAliveTimeout 3
Při zapnutí KeepAlive je vhodné také zvýšit počet maximálně připojených klientů (MaxClients), protože otevřená čekající spojení tento počet zvyšují. Situací, kdy je vhodné KeepAlive v Apache vypnout, je například konfigurace, kdy používáte webový server Nginx jako reverzní proxy pro Apache. O udržování spojení se tak stará on a je zbytečné, aby ho zajišťoval i Apache. Konfigurace s předřazeným reverzním proxy může výkon velmi zlepšit a zajistit větší škálovatelnost celé infrastruktury.
Problém s KeepAlive se tolik netýká webů používajících HTTPS (zabezpečený kanál se vyjednává pouze jednou) a s příchodem HTTP/2 tento problém také odpadne.
Souhrn hlavních bodů článku:
- opensource systémy je třeba pravidelně aktualizovat
- i v systémech na míru mohou být velmi závažné chyby – často v ošetření uživatelských vstupů a v souborovém manažeru
- funkce “odeslat kamarádovi e-mailem odkaz na tento článek” pro svůj účel spíše nefunguje než funguje a zároveň je velmi náchylná ke zneužití
- špatně provedená stránka s chybou 404 může odradit mnoho návštěvníků
- nefunkční odkazy vznikají poměrně jednoduše
- pravidelně kontrolujte své odkazy nástroji jako je Xenu nebo Screaming Frog a nahlížejte do Google Search Console
- mnoho přesměrování 301/302 stránky zbytečně brzdí, ujistěte se, zda jsou tato přesměrování opravdu nutná
- zkuste si, zda je stránkování použitelné i na mobilu
- pokud má stránkování více než 30 stránek a neexistuje jiná forma navigace, je ve většině případů něco špatně
- jednotlivé stránky výpisu většinou neobsahují žádné užitečné informace, často se mění, a tak není nezbytné je nechat indexovat
- velmi často ze zapomíná na nastavení hlaviček pro expiraci a nastavení komprese textových dat
- neoptimalizované obrázky mohou web opravdu velmi zbrzdit
- nevypínejte KeepAlive, pokud k tomu nemáte opravdu důvod
- budoucnost je v protokolu HTTP/2 a kompresní algoritmus Brotli také nevypadá špatně
Toto byl výčet těch nejběžnějších chyb, se kterými se setkávám prakticky každý den. Myslíte, že jsem něco opomenul, je potřeba něco více rozvést, nebo si myslíte, že je nějaký problém častější? Svůj názor můžete vyjádřit v komentáři.
Další informace o ladění výkonu webových stránek naleznete v mém článku Optimalizace výkonu webových aplikací – na co se zaměřit.